設計DataWindow的好習慣:SQL Plan
PowerBuiler中的DataWindow就是SQL Result的視覺化物件。在.net中的物件中類似是DataGrid。
當你設計一個 DataWindow 時,很大的機會都會用到 SQL 查詢。
但是很方便的設計工具,不代表你可以有效的使用它。
雖然我這裡的範例使用的是 ASE SQL Server,
而且 SQL 語句都是在 SQL server 上執行的,
但是本質上 SQL 查詢的指令和模式都有很大的雷同,
所以這裡沒有指定是哪一種 SQL Server ,我要提供的只是觀念。
假設,這裡有個 Table ,結構如圖:
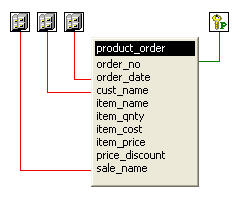 這是一個簡單的訂單資料表,它有4個索引,分別對應
這是一個簡單的訂單資料表,它有4個索引,分別對應
order_no(訂單號,主索引), order_date(訂單日) ,cust_name(客戶) , sale_name(業務員)
如果你在 Datawindow 使用下面這一個查詢:
這樣看起來是沒有問題的,但是如果你使用下面另一個查詢呢?
你認為會如何?差異在哪裡?
如果撇開Table的定義良窳不管的話,第二個 SQL 保證有一天會出問題。
為什麼會這麼說?
重點在 "index - 索引"。
一般而言,任何SQL指令到了 SQL Server 上的時候,如果查詢句柄不帶任何指定的索引,
則代表由 SQL Server 自行決定要使用的索引檔。
索引檔本身會比 Table 來得小、循序或是叢集。
SQL Server 會從 Where 句柄的欄位中找出可能使用索引的欄位,判斷然後加以預測與判斷。
因此,我們看看第一個 SQL 會使用哪個索引?
由於第一個 SQL 中 Where 只用了一個欄位: order_no ,
因此很明確的我們可以知道它"應該"使用的是 order_no的主索引。
那第二個 SQL 呢?
由於 Where 中使用了兩個欄位 order_date、cust_name
這時候你就無法得知 SQL Server 將會使用哪一個索引 order_date?cust_name?
如果不是很熟析 index 與 table 關係的,我稍微複習一下 ,
以上面的 product_order Table為例,如果每天的訂單將近 5000 筆,
一年後就會有 180多萬筆,三年後就會擁有近550萬筆的資料。
也許前一年你的 SQL 語句都沒問題,到了第三年有問題的機會大很多,
這就是我前面說的:保證有一天會出問題。
原因出在資料量。
以 order_no索引 來說,它是unique,雖然它三年後也會有550萬筆資料量,
但是它具有"循序性"與"唯一性"的特性,對 SQL Server 來說,
它只需要"計算"出所在的相對位置,即可取得索引值,
然後取得資料在 product_order 中的位址,進而讀取資料,因此只有一筆資料被 hit 。
但若以 order_date索引 來說,它具有叢集特性,因此 SQL Server 只要找到該日期的叢集區,
級可以一筆筆讀取該日的資料,然後進而比對第二個符合 Where 條件的欄位 。
因此最多這個叢集可以預估約為 5000 筆。
然而 cust_name索引行為就會接近 order_date索引,但是叢集量就比較不確定,
如果該客戶這三年來只有一筆交易,那麼這個 Where 條近的速度會接近 order_no索引,
如果這三年來交易量超過上萬筆,
那麼它的叢集比對數量就會比 order_date索引的5000筆 還要多。
速度上一定比較慢
當然以上是屬於邏輯處理部份,實際上資料在 Server上 存放的位置和
Server 本身的快取配置也會影響到實際速度。
也因此設計一個有效率的 Datawindow 查詢,就得透過一些工具來輔助,
例如在 ASE 的工具裏面就包含了 SQL advantage 這項工具,
SQL advantage 可以在 SQL 執行時,進行所謂的 SQL 計畫 (SQL plan),
你可以在SQL advantage中的 session preferences 中設定,如下:
 如果你是在MS SQL 的 Management Studio 上執行,則是在執行查詢時按滑鼠右鍵可以看到:
如果你是在MS SQL 的 Management Studio 上執行,則是在執行查詢時按滑鼠右鍵可以看到:

當你設定好以後,
我們以上面第一個SQL指令為例,當你執行時後就可以看到SQL server
在分析指令時使用到的相關訊息。
通常你可以看到類似下面的訊息:
注意看到紅色的字段,首先你可以看到 Table 名稱,再來使用的索引檔,最
後就是索引檔裡面的索引鍵。
這樣表示,這次的指令SQL server使用的索引資訊。
因為索引鍵與索引檔剛好都是預期中的判斷。
若是出現下面的指令
則表示該指令無法引用正確的索引,故資料搜尋方式為 Table Scan,
Table Scan 就是從第一筆掃描到最後一筆,你可以知道如果這麼龐大的資料,
這樣的搜尋絕對會花上好一段時間,因此會非常沒有效率。
所以,當你在設計 DataWindow 中的SQL時,要有一個好習慣,
那就是,先到 SQL advantage 裡面,先把要執行的 SQL 指令先 plan 一下,
確認索引沒有問題。
習慣上,除非你的 Where 條件都是使用 primary key 的欄位,
否則最好在 SQL 指令裡強制加上引用的索引檔(index):
如此可以減少未來增加索引後(同質性高的複合索引),
導致 SQL server 判斷錯誤的索引問題。
當你設計一個 DataWindow 時,很大的機會都會用到 SQL 查詢。
但是很方便的設計工具,不代表你可以有效的使用它。
雖然我這裡的範例使用的是 ASE SQL Server,
而且 SQL 語句都是在 SQL server 上執行的,
但是本質上 SQL 查詢的指令和模式都有很大的雷同,
所以這裡沒有指定是哪一種 SQL Server ,我要提供的只是觀念。
假設,這裡有個 Table ,結構如圖:

order_no(訂單號,主索引), order_date(訂單日) ,cust_name(客戶) , sale_name(業務員)
如果你在 Datawindow 使用下面這一個查詢:
Select *
From product_order
Where order_no = 'A090817025'這樣看起來是沒有問題的,但是如果你使用下面另一個查詢呢?
Select *
From product_order
Where order_date = '2009/8/17'
And cust_name = 'John Baskul'你認為會如何?差異在哪裡?
如果撇開Table的定義良窳不管的話,第二個 SQL 保證有一天會出問題。
為什麼會這麼說?
重點在 "index - 索引"。
一般而言,任何SQL指令到了 SQL Server 上的時候,如果查詢句柄不帶任何指定的索引,
則代表由 SQL Server 自行決定要使用的索引檔。
索引檔本身會比 Table 來得小、循序或是叢集。
SQL Server 會從 Where 句柄的欄位中找出可能使用索引的欄位,判斷然後加以預測與判斷。
因此,我們看看第一個 SQL 會使用哪個索引?
由於第一個 SQL 中 Where 只用了一個欄位: order_no ,
因此很明確的我們可以知道它"應該"使用的是 order_no的主索引。
那第二個 SQL 呢?
由於 Where 中使用了兩個欄位 order_date、cust_name
這時候你就無法得知 SQL Server 將會使用哪一個索引 order_date?cust_name?
如果不是很熟析 index 與 table 關係的,我稍微複習一下 ,
以上面的 product_order Table為例,如果每天的訂單將近 5000 筆,
一年後就會有 180多萬筆,三年後就會擁有近550萬筆的資料。
也許前一年你的 SQL 語句都沒問題,到了第三年有問題的機會大很多,
這就是我前面說的:保證有一天會出問題。
原因出在資料量。
以 order_no索引 來說,它是unique,雖然它三年後也會有550萬筆資料量,
但是它具有"循序性"與"唯一性"的特性,對 SQL Server 來說,
它只需要"計算"出所在的相對位置,即可取得索引值,
然後取得資料在 product_order 中的位址,進而讀取資料,因此只有一筆資料被 hit 。
但若以 order_date索引 來說,它具有叢集特性,因此 SQL Server 只要找到該日期的叢集區,
級可以一筆筆讀取該日的資料,然後進而比對第二個符合 Where 條件的欄位 。
因此最多這個叢集可以預估約為 5000 筆。
然而 cust_name索引行為就會接近 order_date索引,但是叢集量就比較不確定,
如果該客戶這三年來只有一筆交易,那麼這個 Where 條近的速度會接近 order_no索引,
如果這三年來交易量超過上萬筆,
那麼它的叢集比對數量就會比 order_date索引的5000筆 還要多。
速度上一定比較慢
當然以上是屬於邏輯處理部份,實際上資料在 Server上 存放的位置和
Server 本身的快取配置也會影響到實際速度。
也因此設計一個有效率的 Datawindow 查詢,就得透過一些工具來輔助,
例如在 ASE 的工具裏面就包含了 SQL advantage 這項工具,
SQL advantage 可以在 SQL 執行時,進行所謂的 SQL 計畫 (SQL plan),
你可以在SQL advantage中的 session preferences 中設定,如下:


當你設定好以後,
我們以上面第一個SQL指令為例,當你執行時後就可以看到SQL server
在分析指令時使用到的相關訊息。
通常你可以看到類似下面的訊息:
QUERY PLAN FOR STATEMENT 1 (at line 1).
STEP 1
The type of query is SELECT.
FROM TABLE
product_order
Nested iteration.
Index : PK_PDT_ODR_NO
Forward scan.
Positioning by key.
Keys are:
order_no ASC
Using I/O Size 2 Kbytes for index leaf pages.
With LRU Buffer Replacement Strategy for index leaf pages.
Using I/O Size 2 Kbytes for data pages.
With LRU Buffer Replacement Strategy for data pages. 注意看到紅色的字段,首先你可以看到 Table 名稱,再來使用的索引檔,最
後就是索引檔裡面的索引鍵。
這樣表示,這次的指令SQL server使用的索引資訊。
因為索引鍵與索引檔剛好都是預期中的判斷。
若是出現下面的指令
FROM TABLE
product_order
Nested iteration.
Table Scan.
Forward scan.
Positioning at start of table.
Using I/O Size 2 Kbytes for data pages.
With LRU Buffer Replacement Strategy for data pages. 則表示該指令無法引用正確的索引,故資料搜尋方式為 Table Scan,
Table Scan 就是從第一筆掃描到最後一筆,你可以知道如果這麼龐大的資料,
這樣的搜尋絕對會花上好一段時間,因此會非常沒有效率。
所以,當你在設計 DataWindow 中的SQL時,要有一個好習慣,
那就是,先到 SQL advantage 裡面,先把要執行的 SQL 指令先 plan 一下,
確認索引沒有問題。
習慣上,除非你的 Where 條件都是使用 primary key 的欄位,
否則最好在 SQL 指令裡強制加上引用的索引檔(index):
Select *
From product_order (index PD_ODR_DTM)
Where order_date = '2009/8/17'
And cust_name = 'John Baskul'如此可以減少未來增加索引後(同質性高的複合索引),
導致 SQL server 判斷錯誤的索引問題。



留言